Theses
Below you find the currently available projects. If you are interested in any of these topics (even those that are already “assigned”), feel free to contact me at anna.bernasconi@polimi.it for further ideas/details!
New master theses proposals
Comparison of legislative text from Italian, US and Australian law corpora, using graph-based and topic analyses

The proposed thesis aims to explore new ways of managing and analyzing the landscape of legislative data (i.e., laws/bills/acts), across multiple countries (Italy, USA and Australia). In particular, it will make use of graph databases, to represent the Knowledge Graph of the legislation, possibly annotated with relevant topics in laws and enriched by external sources’ information such as governments/legislatures.
The aim is to leverage this structure to design quantitative data analytics and complex network analysis. The student will propose and implement metrics that can be used to compare both qualitatively and quantitatively the three systems. In addition, the student will industrialize the ETL processes in order to offer on a dedicated web platform up-to-date legislative information together with the possibility of conducting live systems comparison analysis.
Prospective candidates should hold previous experience with the PyData stack (including pandas, scipy, scikit-learn, etc.), PyTorch, graph databases (e.g., Neo4j) and a front-end framework (e.g., Angular). Additionally, familiarity with current Large Language Model (LLM) architectures and trends is suggested.
Warning system for viral genomic surveillance in public health contexts

This master thesis will deal with analyzing previously developed methods for the identification of new viral variants and recombined genomes (specifically for SARS-CoV-2, the virus responsible for COVID-19) and automatize them on a big data scale to build a warning system for genomic surveillance. Resources: Paper 1, Paper 2, Paper 3
Design and implementation of a unifying FAIR repository for genomic tracks
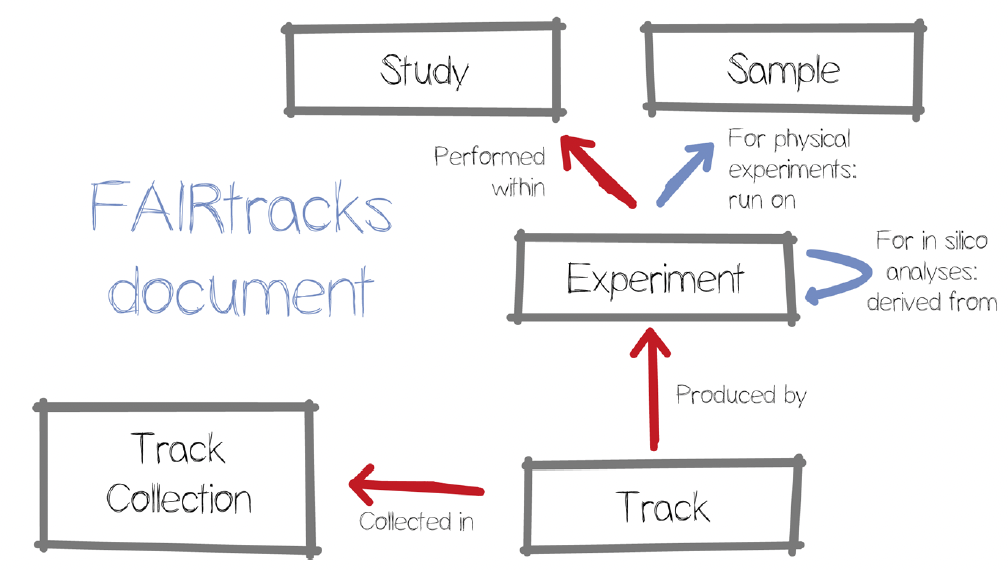
FAIR is an acronym that describes the characteristics of a data resource of being Findable, Accessible, Interoperable, and Reusable. In this thesis, you are going to deal with FAIR genomic annotations, a specific data type that is very useful in genomic research. First, we are going to design a minimal FAIR metadata schema for genomic annotations that builds on the existing FAIRtracks metadata schema, further harmonised with relevant data models such as from the Genomic Conceptual Model.
We will then build 1) an actual infrastructure that adopts the schema, which should support scalable and maintainable data flows for transforming existing metadata sources to support the minimal schema (exploiting the Omnipy Python library) and 2) a standardised API for downstream search and discovery that works independently of a particular implementation of a search service.
This thesis will be run in the context of the FAIRification of Genomic Annotations Working Group of the Research Data Alliance, collaborating with scientists of many institutions.
Resources: https://f1000research.com/articles/10-268, https://doi.org/10.1007/978-3-319-69904-2_26, https://doi.org/10.1109/TCBB.2020.2998954, https://doi.org/10.1093/database/baz132
Ongoing theses projects
Advanced topic modeling and classification framework for legal text
The proposed thesis aims to explore advanced topic modeling techniques by extending an existing framework, Topics’ Evolution That You See (TETYS), to support multi-topic modeling capabilities, specifically applied to the domain of legal texts. The research will begin by evaluating and comparing current approaches for topic modeling and topic extraction. Based on these findings, the focus will shift to designing and developing an extension of the TETYS pipeline that enables multi-topic assignment. This enhanced approach will then be applied to a collection of laws and legal documents to create a comprehensive multi-topic model.
Prospective candidates should hold previous experience with the PyData stack (including pandas, scipy, scikit-learn, etc.) and PyTorch. Additionally, familiarity with current Large Language Model (LLM) architectures and generative NLP techniques is suggested.
Analysis of convergent evolution in SARS-CoV-2 impacting anti-viral therapies
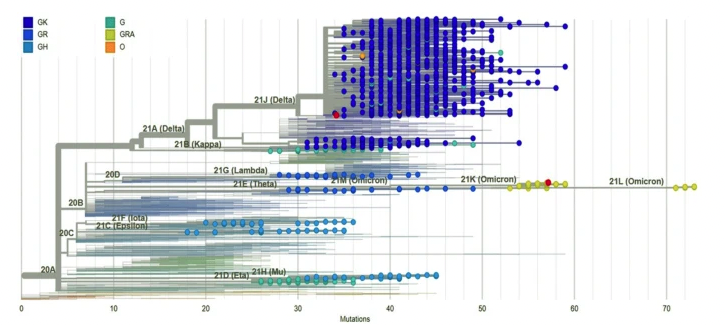
Study of convergent evolution of different mutations along the phylogenetic tree (describing the evolution of a viral species). We will focus on the mutations that escape antiviral drugs, then extend the analysis in a database-wide fashion focusing on specific parts of the tree. The objective is to identify clusters of variants that are associated by acquiring same convergint mutations. In this thesis, you will also produce a visualizer to allow immunologists to navigate the data stracture that embodies the convergent evolution information.
Resources: https://doi.org/10.3390/ijms24032264
Building user interfaces for dynamic topic modeling visualization and exploration
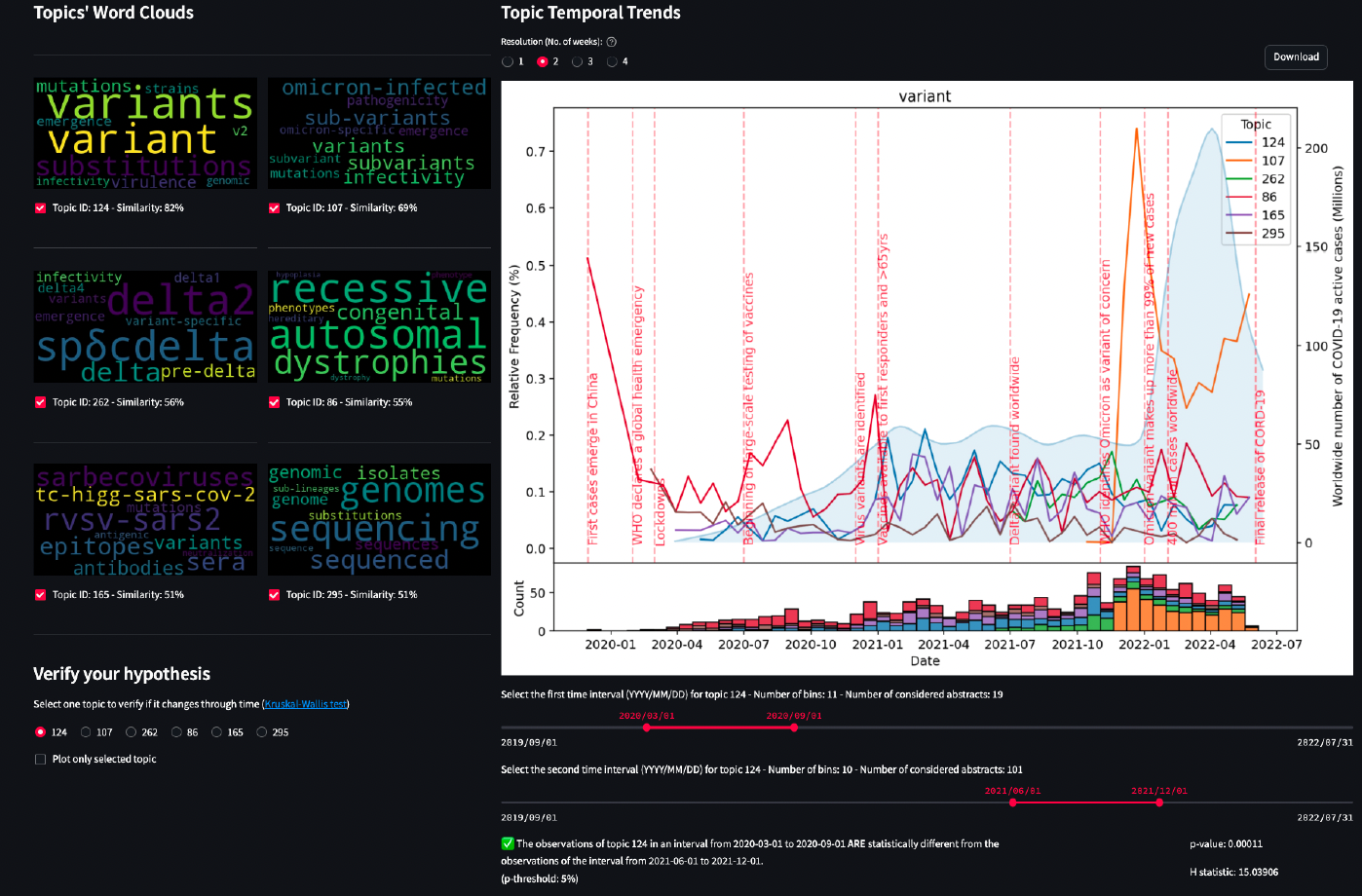
A topic model is a statistical model for discovering abstract topics that are mentioned in a collection of textual documents. We built a pipeline that can extract relevant topics from a big corpus of research abstracts and build a dashboard for inspecting temporal trends of topics related to COVID-19 research (http://gmql.eu/cortoviz/). We are looking for a skilled master student who is passionate about UX design and is willing to completely design and implement an appealing user interface for making users flexibly discover all the results that can be extracted from the topic modeling architecture.
Concluded theses projects
A data-driven approach for storing and analyzing Causal Loop Diagrams
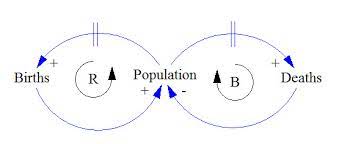
Systemic Design aims to grasp the intricate behavior of socio-technical systems; their hidden patterns are unveiled by making use of Causal Loop Diagrams (CLDs), that visually represent systems’ behaviors at an abstract level. In these diagrams, nodes represent variables shaping a system’s dynamics, while edges highlight causal relationships, emphasizing the interplay between nodes. Loops, as cyclic paths from one variable back to itself, are categorized as either balancing (B) or reinforcing (R), shedding light on the system’s inherent dynamics. CLDs find applications across various domains, from urban planning and environmental sustainability to organizational management and public health.
Our step forward in the study of CLDs is the recent design of an innovative metamodel, which serves as the foundation for a systematic approach to understanding CLDs. In your thesis, your task will be to create a dynamic repository that not only houses our metamodel but also enables systematic analysis of any given system. By documenting nodes and edges, extracting loops, and categorizing them, you will exploit data-driven methods for discovering critical aspects of socio-technical systems.
User validation studies for domain-specific search systems

Within our research lab, we built two search systems for COVID-19-related literature. This master thesis will deal with exploring available user-centered validation techniques, with the aim of conducting two empirical studies on actual users, using the testbed implementations of the two applications. The student will propose a set of experiments, conduct them, and perform data collection, analysis, and reporting of results with visualizations. The drawn conclusions will be reported along the typical guidelines of empirical studies and will be employed to inform future implementation phases.
FAIRness assessment of biological and virological data sources
FAIR is an acronym that describes the characteristics of a data resource of being Findable, Accessible, Interoperable, and Reusable. This master thesis will deal with exploring human and viral genomic databases. A small set of important sources will be selected, and a wide FAIRness assessment will be performed both with existing automatic assessment tools and developing a novel pipeline for semi-automatic assessment. Both qualitative and quantitative methods will be employed.
Resources: Paper 1, Paper 2, Paper 3, Paper 4
Evolving topic modeling architecture for discovery on Sustainable Development Goals in text documents
The student engaging in this project deals with re-purposing existing pipelines for data preparation, topic modeling processing, and visualization. We apply the architecture to study how the United Nations Sustainable Development Goals, https://www.undp.org/sustainable-development-goals) are addressed across scientific literature in time. A corpus of scientific abstracts will be selected and prepared for use.
The student will extend the current CORToViz pipeline and tool to become incremental, keeping the tool online and updated with new abstracts to see, from month to month, what is emerging and to c Classify emerging topics.
Starting reading material: Paper 1, Paper 2
Data science for surveillance of avian influenza

This master thesis will deal with understanding previously developed methods for the identification of new viral variants and recombined genomes (specifically for SARS-CoV-2, the virus responsible for COVID-19) and re-purposing them to develop similar methods for the avian influenza viruses.
- Building reactive processing rules for knowledge graphs
- Exploring and searching the CORD-19 big data corpus for supporting COVID-19 research
- Variant Hunter: a tool for fast detection emerging SARS-CoV-2 variants
- Integration of genome-wide association studies into the GeCo repository
- Automatic data integration for genomic metadata through sequence-to-sequence models
- Integration of DNA variation data into a GDM repository and API development for identification of genomic populations
- Ontology-driven metadata enrichment for genomic datasets
- Progettazione e realizzazione di una procedura di integrazione per dati genomici